< XSLT - Transforming XML 1 | Main | C++ .NET and Using ADO.NET 1 >
XSLT - Transforming XML 2
What we have in this page?
-
Using XPath with XPathNavigator
-
Basic XPath Syntax
-
Using XSL
-
The Basics of XSL Style Sheets
-
A Very Quick Reference
Using XPath with XPathNavigator
Now that you know how to create and use an XPathNavigator, let’s move on to XPath itself. The XPath expression language is very complex and capable of defining extremely precise matches. This module isn’t the place for anything like a full explanation of XPath expressions, but you’ll find an introduction to the topic in the following section. For more details about XPath, you may want to consult the XML SDK documentation provided by the Microsoft Developer Network (MSDN).
Basic XPath Syntax
In case you haven’t encountered XPath before, here is an introduction to the simplest XPath syntax. XPath uses pattern matching to create expressions that match one or more elements within a document. You create basic expressions using element names, with child relationships denoted by forward slash marks (/). The syntax is very similar to specifying file and directory paths. For example, foo/bar specifies bar as a child of foo. When passed to an XPath processor and evaluated, it will match all bar elements that are children of foo elements. A leading slash mark means that the search should begin at the root, an asterisk matches any element, and two slash marks (//) will match any number of levels in the tree. Here are a few more examples:
Simple conditionals can be represented with square brackets ([]), so order[subtotal] will match order elements that have a child subtotal element. To match attributes, use an at sign (@) sign, which is short for attribute. So, volcano[@name] will match all volcano elements that have a name attribute. When an XPath engine evaluates an expression, it returns a list of the nodes that match, and this list might contain zero, one, or more nodes. It’s important to note that these nodes are now completely out of context and you can’t tell where in the document they occur or what relationship they have to one another. You can use XPath to select a set of nodes using the Select function of XPathNavigator, as demonstrated in the following brief exercise.
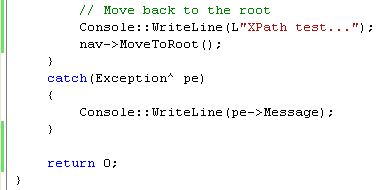
11. Continue with the project that you used for the previous exercise. Add the following code at the end of the code in the try block, which will set the XPathNavigator back to the top of the document tree:
|
12. Add the following code that will select all the volcano elements that are children of geology:
// Select all ’volcano’ elements that are children of ’geology’
// and have a ’comment’ child, starting at the root
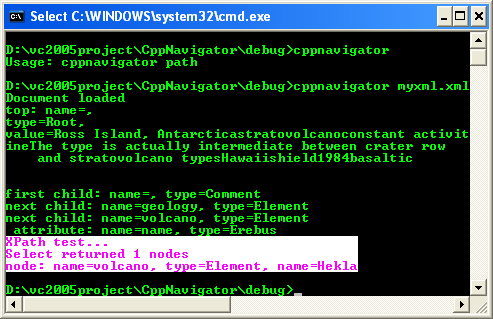
XPathNodeIterator^ xpi = nav->Select(L"/geology/volcano");
Console::WriteLine(L"Select returned {0} nodes", (Object^)(xpi->Count));
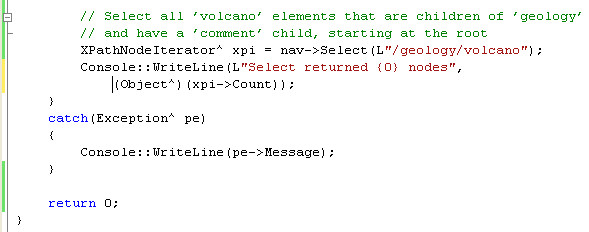
The Select function takes a string representing an XPath expression and passes it to the XPath engine. The function returns an XPathNodeIterator^ that you can use to iterate over the set of nodes retrieved by the XPath engine. You can find out how many nodes were retrieved by using the Count property on the XPathNodeIterator.
13. XPathNodeIterator is basically an enumerator, so it supports the MoveNext method and the Current property. Add the following code that will print details of all the elements in the node list:
while (xpi->MoveNext())
{
XPathNavigator^ xpn = xpi->Current;
Console::Write(L"node: name={0}, type={1}", xpn->Name,
((Object^)(xpn->NodeType))->ToString());
xpn->MoveToFirstAttribute();
Console::WriteLine(L", name={0}", xpn->Value);
}

As usual, MoveNext moves from item to item in the collection. You might expect Current to return you a pointer to a node, but it actually returns a pointer to another XPathNavigator, which you use to investigate the tree of elements under the current item. The Write statement writes the node name and type, and then you retrieve the first attribute, which holds the name of the volcano.
14. Build and run the program. You should get something similar to the following output:
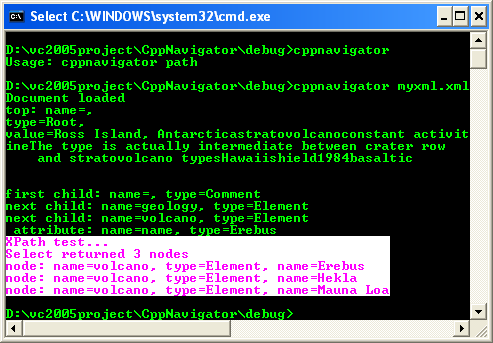
15. Modify the expression to return only those volcano elements that have a comment child element, as shown here:
XPathNodeIterator^ xpi = nav->Select(L"/geology/volcano[comment]");
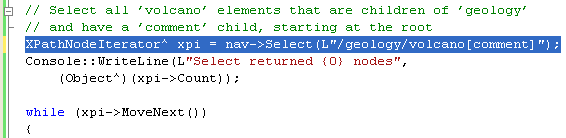
16. Rebuild and re-run your application. You should now get only one child node returned because only Hekla has a comment child node.
If you’re going to use the same XPath expression several times, you can compile it to produce an XPathExpression. This object can be used instead of a string in calls to Select statements, and it cuts out the text parsing step.
Using XSL
To transform a document using XSL, you need to create a style sheet that defines the transformation and then pass the style sheet to the XSL processor. The first important thing to note is that XSL style sheets are simply XML documents. They have all the familiar syntax and are written, structured, and processed in just the same way as any other XML document. XSL transformations are handled using the XslTransform class from the System::Xml::Xsl namespace. The class has only three members and is very simple to use. Here’s the typical sequence you follow to apply a transformation:
-
Create an XslTransform object.
-
Use its Load method to load the style sheet from a file, a URL, an XmlReader, or an XPathNavigator.
-
Call the Transform method to perform the transformation. You can input and output data in a number of ways, as you’ll see in the following exercise.
The following short exercise will show you how to process XML using an XSL style sheet. Like XPath, XSL is too complex to introduce in any detail here, but if you haven’t met XSL before, you’ll find basic details in the following section, “The Basics of XSL Style Sheets.”
The Basics of XSL Style Sheets
This brief explanation of how XSL style sheets work should help you understand the one used in the exercise. First, XSL style sheets are simply another type of XML document, so they have to obey all the usual rules. They start with an XML declaration, they contain a single root element, and all elements must nest and be closed correctly. An XSL style sheet is defined by a stylesheet element, which has to define the XSL namespace and the version attribute. This namespace has to use the correct URL; otherwise, the element won’t be recognized as an XSL style sheet. It’s normal for the namespace prefix to be xsl, but this prefix isn’t essential.
XSL works by specifying templates that use XPath expressions to match sets of nodes in the document. The following example style sheet defines one template that matches the root element. When the style sheet is processed, the XSL engine looks at the body of the template and applies it to the node list. Any other XSL commands are processed, and anything it doesn’t recognize as an XSL command gets echoed to the output. In this example, the HTML isn’t recognized as XSL commands, so it’s echoed to the output. Note that content such as the HTML is still processed by the XSL processor, so it has to be valid XML. All elements must be correctly nested and must have closing tags. There are a number of XSL commands, two of which are used in the following exercise. The xsl:for-each command provides a looping construct that loops over all the nodes that match the current template. The xsl:value-of command typically retrieves the value of an element or attribute. You can see in the exercise how the two attributes of the height element are used to build the contents of the table cell.
The following is the style sheet file named myxsl.xsl that we’ll use to transform the XML. It contains one template that matches the root element and then prints out some of the fields for each volcano element in a table.
<?xml version="1.0" encoding="utf-8" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="/geology">
<html>
<head>
<title>Volcanoes</title>
</head>
<body>
<h1>Volcanoes</h1>
<table width="75%" border="1">
<tr>
<th>Name</th>
<th>Location</th>
<th>Height</th>
<th>Type</th>
</tr>
<xsl:for-each select="volcano">
<tr>
<td><xsl:value-of select="@name"/></td>
<td><xsl:value-of select="location"/></td>
<td><xsl:value-of select="height/@value"/>
<xsl:value-of select="height/@unit"/></td>
<td><xsl:value-of select="type"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
The following steps are on the how to use this style sheet to transform the XML.
1. Create a new Visual C++ CLR Console Application project named CppXsl.
2. Add the following four lines to the top of CppXsl.cpp:
#using <System.xml.dll>
...
...
...
using namespace System::Xml;
using namespace System::Xml::XPath;
using namespace System::Xml::Xsl;
The code for the XML classes lives in System.xml.dll, so it needs to be included via a #using directive. It’s easier to use the classes if you include using directives for the three XML namespaces, as shown in the preceding code.
3. You’re going to supply the names of the XML document to transform and the style sheet to use when you run the program from the command line, so change the declaration of the main() function to include the command-line argument parameters, like this:
// Get the command line arguments
args = Environment::GetCommandLineArgs();

4. Add the following code to the start of the main function to check the number of arguments and save the paths to the XML document and the XSL style sheet:
// Check for required arguments
if (args->Length < 3)
{
Console::WriteLine(L"Usage: {0} xml-file stylesheet_file", args[0]);
return -1;
}
String^ path = gcnew String(args[1]);
String^ xslpath = gcnew String(args[2]);

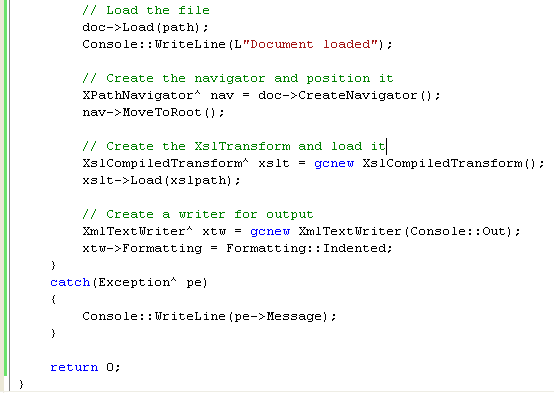
5. Now that you’ve got the paths, create an XmlDocument to parse the file and load it into a DOM tree.
try
{
// Create the XmlDocument to parse the file
XmlDocument^ doc = gcnew XmlDocument();
// Load the file
doc->Load(path);
Console::WriteLine(L"Document loaded");
}
catch(Exception^ pe)
{
Console::WriteLine(pe->Message);
}
 |
As before, it’s a good idea to be prepared to catch exceptions when using XmlDocument because it will throw exceptions if it encounters any problems with opening or parsing the file.
6. Now create in the try block an XPathNavigator that uses the XmlDocument, and position it at the root. Add the following code, and any code presented further in this exercise, to the end of the try block:
// Create the navigator and position it
XPathNavigator^ nav = doc->CreateNavigator();
nav->MoveToRoot();
7. Create an XslCompiledTransform (previous version is XslTransform) object, and load the style sheet, as shown here:
// Create the XslTransform and load it
XslCompiledTransform^ xslt = gcnew XslCompiledTransform();
xslt->Load(xslpath);
The Load function loads the style sheet, parsing it just like any other XML document. Always put calls to Load inside a try block to catch file loading and parsing errors. Load can also take its input from an XmlReader or an XPathNavigator.
8. The output from this transformation is going to be HTML, so it would be useful to output it properly formatted. As you saw in the previous module, XmlTextWriter is used to output formatted XML, so you can create an XmlTextWriter to write output to the Console by using the following code:
// Create a writer for output
XmlTextWriter^ xtw = gcnew XmlTextWriter(Console::Out);
xtw->Formatting = Formatting::Indented;
9. Now you can perform the transformation, like the following. Add this code.
// Do the transformation
xslt->Transform(nav, nullptr, xtw);
The first argument to Transform is the source of the XML, which in this case is an XPathNavigator. The second argument, which we’re not using, lets you pass data into the transform using an XslArgumentList object. The third argument specifies the destination for the output, which is the Console via the XmlTextWriter.
10. Make sure myxml.xml and myxsl.xsl files are under the project’s debug directory else you need to provide full path to those files.
11. Build and run the program from the command line, specifying the names of the XML and XSL files. You should see HTML output such as this:
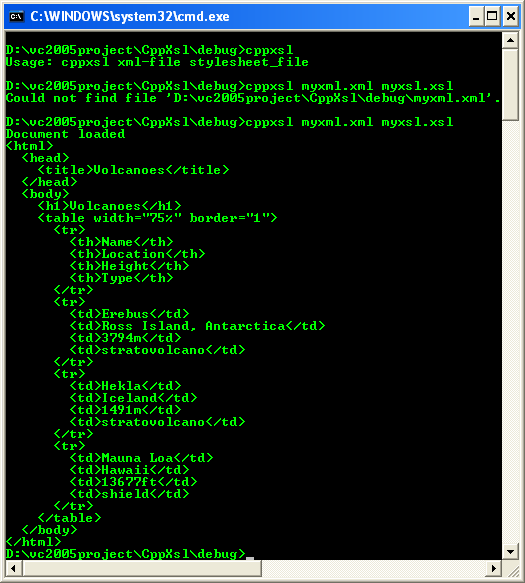
The data has been extracted from the XML file and merged with HTML to create the output through the console.
12. Next let create the HTML file for the transformed XML. Change the third parameter of the XmlTextWriter to the HTML file. Change the following code. The myhtml.html is the HTML file that will be created that contain the transformed XML.
// Do the transformation
xslt->Transform(nav, nullptr, xtw->Create("myhtml.html"));

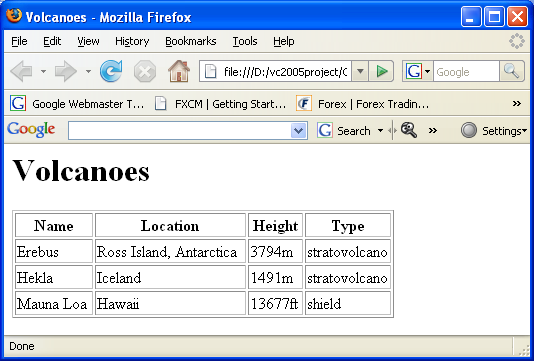
13. Rebuild and re-run the application. The following figure shows the created HTML file and how the output looks in a browser.

A Very Quick Reference
| To | Do this |
| Navigate forward and back over an XmlDocument. | Create an XPathNavigator. |
| Select nodes based on XPath expressions. | Use the Select function of XPathNavigator. |
| Transform XML using an XSL style sheet. | Create an XslCompiledTransform (old version is XslTransform) object, load the style sheet using the Load method, and then call the Transform method to perform the transformation. |
|
Table 3 | |
Part 1 | Part 2